
|
| || Home || Projects || Publications || Members || |
| PhenoMining | SNRS | ISP | CoXML | KMeX | KMeD | CoBase | Data Mining |
CoBase1. IntroductionWhen making daily decisions, humans seldom have complete or exact information. Yet, traditional query processing systems accept only precisely specified queries, requiring users to fully understand the problem domain and the database structure and content. Further, traditional systems offer only exact answers, returning null information if the precise answer is not available. CoBase is an extension to the conventional database notation that remedies these shortcomings. For example, a pilot can ask a conceptual query, "Find a nearby friendly airport where an F-15 can land." The approximate operator, nearby, is translated into a distance range based on the position of the aircraft, and F-15 is translated into the required runway length and width for landing. CoBase also returns relevant (associative) information such as weather and runway conditions at the airport. Associative information is user and context sensitive. Another example as shown in the figure is "Find hospitals similar to St. John's (based on staff and surgical facilities) near LAX." CoBase ranks the answers based on the similarity of the specified attributes to those of St. John's. For the query, "Find a seaport with railroad facility in Los Angeles," if there are no such seaports in LA, CoBase can relax LA to Long Beach (using domain knowledge) and finds a seaport in Long Beach with railroad facility. 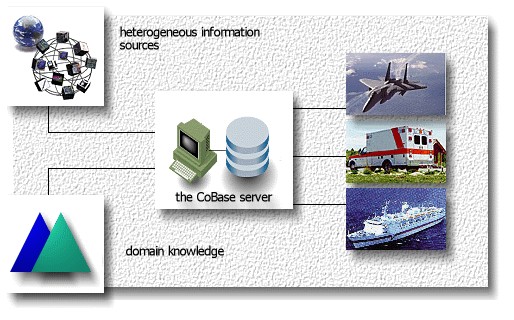 The generality of the CoBase relaxation technology allows it to be extended to the following new areas:
2. ArchitectureThe following illustration shows the general architecture of the CoBase system. More details on each aspect of the diagram can be obtained by following the links below.
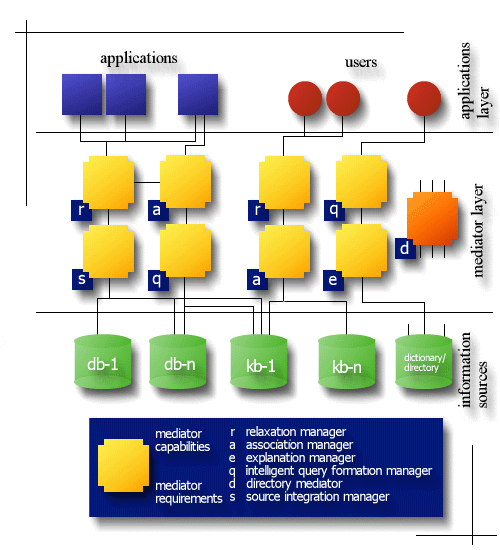 
A Mediator is software module that takes some input set of information, intelligently analyzes the information from a specific viewpoint, and produces a set of conclusions based on its analysis. Oftentimes a Mediator needs additional information (knowledge and/or data) to perform its analysis. This information can be required as inputs to the Mediator's analysis or, more practically, the Mediator can seek the assistance of other Mediators in fulfilling its information needs. This latter mode (Mediators assisting Mediators) is the notion that dynamic matching will be introduced for. Specifically, a Mediator with an information need will report this need to the environment and dynamically match with the Mediators that can fulfill the need. Our use of Mediators to decompose the cooperative query answering capabilities, where:

Query relaxation is the process of understanding the semantic context and intent of a user query and massaging the query constraints into "near" values that provide "best-fit" answers. Relaxation is a knowledge-based approach to query answering that can provide counter-intuitive and over zealous responses when applied in an uncontrolled manner. Thus, when relaxation is applied in I3 systems, it must be controlled and available for user-oriented modification and adjustment. A relaxation mediator provides operations such as approximately-to, similar-to, or near-to on specific data schemas and/or types. In addition, a relaxation mediator searches for approximate answers automatically whenever a user query is over or ill specified. Using external knowledge sources, the mediator answers a query by applying controlled rewriting and relaxation of query terms such that the input query is answered to a high level of accuracy and interpretation. Our specific relaxation mediators use a knowledge structure termed Type Abstraction Hierarchy (TAH) to assist in approximately answering queries. Furthermore, we allow the input query to be annotated with control parameters to help guide the mediator in the application of query relaxation. Our current work has developed methods to use, acquire, and adapt TAHs for traditional structured data records (i.e., database relations or ASCII-based objects). In the proposed work, we extend our relaxation mechanisms to handle feature-based image and evolutionary data types. The integration of our record-based, image-based and evolution-based query relaxation into the I3 architecture provides a unique approach to accessing information in the totality. A specific relaxation mediator will provide some subset of the relaxation capabilities, and the mediator infrastructure will facilitate the subsequent interoperation of mediators during query processing. In the remainder of this section, we explain the TAHs we will use, acquire, and adapt for query processing. Furthermore, we explain how the user is provided external control of the default query relaxation process. 
Our associative query answering facility provides relevant information not explicitly requested in a user query. Case-Based Reasoning paradigm is employed to integrate previous experience to control the association. 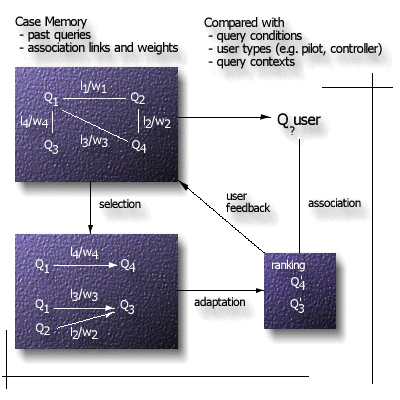
The Case Memory consists of cases and association links. Cases are past user queries (e.g., Q1, Q2, Q3, or Q4). An association link (e.g., l1) is established by the attributes shared by the two cases (e.g., Q1, Q3), and the corresponding weight (e.g., w1), represents the usefulness of the association between the two cases. When a user query (Quser) is executed, its conditions, user type and context are compared against the Case Memory for similar cases (e.g., Q1 and Q2 are similar to Quser). Based on the set of similar cases, a set of association subjects (Q4 and Q3) can be selected through the traversal of association links (l2, l3, l4). The rank of an association is computed from the similarity measure of the corresponding case and the weights of the association links traversed. The ranking represents the usefulness of the case for the association. The cases with the high usefulness values (e.g., Q3 and Q4) are adapted into the user query, and provides associations to the user. Initially, the Case Memory has not acquired any experience. User feedback on the usefulness of the associations is incrementally integrated into the Case Memory, thus, the weights of the association links traversed are adjusted. In this way, the Case Memory can accumulate experience and improve the associations from the user feedback. 
Cooperative query answering such as query relaxation and association is an inference process involving many databases and knowledge bases. Thus, it is vital to provide explanations about these cooperative operations so that users can fully understand and trust the answers derived from those operations. An explanation system is developed to serve this purpose. 
Explanations may occur at many points during processing. Simple rules associated with a user model determine when and what explanation goals are posed. One extreme is the system running automatically, only summarizing its work once it has completed. Another extreme is the system running in detail, explaining each query transformation. The Explanation System may run in any mode along this continuum. To provide explanations, the Explanation Invocation Module takes the action traces generated by the cooperative operations, selects a set of templates and their ordering based the explanation goal and action traces, and produces English text by filling in the templates with the information from the traces. To select and order the templates, it utilizes the Expect Planner developed at ISI/USC. With this dynamic planning capability, the Explanation System allows a user to interactively choose any sub-parts of a given explanation (e.g., paragraphs, sentences, or words) for more definition, elaboration, justification, and summarization. 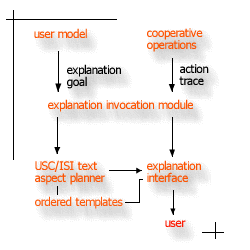 Templates and user models are provided by domain experts.
Templates are associated with
trace types, not specific instances. Thus they
can be generalized over all queries of a given type.
The templates
have a clear syntax, and can quickly be generated or changed
to produce the actual English of the explanations.
The Explanation system
is able to give explanations
at a proper level of details to a user based on the user model/type. 
In a large information system, the size and complexity of the schema often makes it difficult for the user to pose a query. If the user does not know exactly how to formulate the query, he consults an expert to assist him. This motivated us to develop an Intelligent Query Interface (IQI) to interactively assist the user with the query formation process. Consider a transportation database containing information about aircrafts, ships, military installations, countries, etc. A user query: Which airports can land a C-5 cargo plane? The user is presented with 13 high level concepts describing 52 DB tables. In this case, airport and aircraft are the two high level concepts selected by the user. Further, airports and aircraft_airfield_chars are the two relevant DB tables respectively. The user then specifies query conditions (e.g., aport_nm = ?, ac_type_name = C-5) for these DB tables. Notice that selecting the DB tables from the query statement might be a non-trivial task. Presentation of the high level concepts to the user simplifies this selection process. 3. DemoThe following video clip demonstrate different functionalities of the CoBase system. If you have trouble viewing the video above you can click the links below to download and view. Each video clip is about two minutes long. Part One In this first part of the demo, we introduce the explicit relaxation
operators: ~ (APPROXIMATE) and NEAR-TO. Both operators are context sensitive. Part Two In this part of the demo, we discuss one of the relaxation control
operators: RELAX-ORDER. This operator allows users to specify the exact
order of relaxation for each query condition. 4. Publications4.1 CoBase
4.2 TAH
|
|
Powered by CoBase Research Group Last updated on July 19, 2006 |





