
|
| || Home || Projects || Publications || Members || |
| PhenoMining | SNRS | ISP | CoXML | KMeX | KMeD | CoBase | Data Mining |
An Inference-based Approach to Data Access Violation Detection and Privacy ProtectionProject funded by NSF Grant # 0313283
Knowledge-based Inference Techniques to Ensure the Security of Database Content.Malicious users can exploit the correlation among data to infer sensitive information from a series of seemingly innocuous data access. To address this inference problem, we develop an inference detection system that resides at the central directory site. Because inference channels can be used to provide a scalable and systematic sound inference, we need to construct a semantic inference model (SIM) that represents all the possible inference channels from any attribute in the system to the set of pre-assigned sensitive attributes. The SIM can be constructed by linking all the related attributes that can be derived via attribute dependency from data dependency, database schema and semantic related knowledge. To reduce inference computation complexity, the instantiated SIM can be mapped into a Bayesian network. Thus, we can use available Bayesian network tools (e.g. SamIam) to evaluate the inference probability along the inference channels. For a single user, when a user poses a query, the detection system will examine his/her past query log and calculate the probability of inferring sensitive information. The query request will be denied if it can infer sensitive information with the probability of exceeding the pre-specified threshold [3]. For multi-user, the users may collaborate with their query answers to increase the probability of inference sensitive information. We can construct a task-sensitive social network based on the users' profiles and questionnaire data [4, 1], which can be utilized to derive collaboration levels among users. Collaborative inference from multiple users can be derived based on their respective collaboration levels, their corresponding query log sequences and the relationship with the inference channel (e.g. with or without overlap) for the sensitive information.
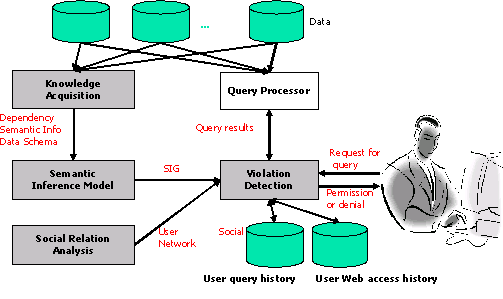
Privacy Protection via Inference Techniques.Privacy is one of the important research issues in building next-generation information systems. The confidentiality problem is further challenged by the growing popularity of Social Network Services such as Friendster, Blogger and Myspace. People in these societies not only publish their own personal profiles (e.g. age, gender, interests), but also reveal their social relations such as friends and family. As friends can affect each other and share common attributes, it is possible to infer your personality by the types of friends you associate with. In other words, even though sometimes you wish to hide some sensitive information, malicious users may be able to infer such information from your friends. Most existing industry privacy protection techniques (e.g. P3P) and government policies (e.g., the HIPPA Privacy Rule) are inadequate in handling these aspects.To address this issue, we studied the impact of social relations on privacy disclosure and privacy protection techniques. Specifically, we use Bayesian networks to model the social network so as to capture the causal relationship among friends. We studied the privacy disclosure in social networks with influence strength, prior probability and society openness. Our experimental studies show that privacy can be inferred with high accuracy from friends that are connected with strong relations [4]. We are currently investigating effective privacy protection techniques. Our preliminary study reveals that selectively hiding or falsifying information based on the characteristics of social networks. Both experimental results and analysis show that these methods are much more effective than randomly alter information [2].
References:
|
|
Powered by CoBase Research Group Last updated on July 10, 2008 |